血糖监测的个人定制:一个人的临床试验 费城加菲猫2019-05-11 02:34:43
现今的时代,患糖尿病的人数迅速增加,这种病已经成为遍及全球的流行病。什么是II-型糖尿病(Type-II Diabetes)?
II-型糖尿病是一种令患者血糖水平过高的疾病。这种病会妨碍血糖从血管进入细胞,令细胞无法得到所需的能量,最终使身体的重要器官严重受损。这种病也会妨碍血液循环,导致失明、肾病,脚趾或腿部也可能因组织坏死而要被切除。大部分糖尿病患者都死于心脏病突发或中风。最近医学界也发现这个病使人更容易患上痴呆症。
在患上II-型糖尿病之前,患者通常已经处于糖尿病前期(Pre-Diabetes),也就是血糖水平稍为高于正常。糖尿病和糖尿病前期的区别在于,II-型糖尿病目前是一种只能控制,不能治愈的病,但那些糖尿病前期的人经过对生活习惯的控制,血糖可以回到正常水平。但是,糖尿病前期没有任何明显病征,因此不容易察觉。一些报告指出,全球约有3亿1600万人处于糖尿病前期,但当中有很多都不知道自己是患者。在美国,大约有九成糖尿病前期患者都不知道自己有这个病。
早在2001年,本猫已经意识到自己会很容易患上糖尿病。原因有四个:(1) 亚裔属于糖尿病高危人群;(2) 家族中有人患糖尿病;(3) 体重指标偏高(BMI>25);每天坐着的时间过长(工作和休闲的大部分时间都是坐着的)。本猫决定要注意自己的血糖水平。作为一个生物统计师,本猫对于数据具有一种职业上的热爱,开始注意收集储存这些血糖数据。最简单的来源是每年的年度体检报告。

可以很明显的观察到,随着年龄的增加,隔夜空腹的血糖指标也在不断升高。
然而,对于糖尿病高危人群和已处在糖尿病前期的人群来说,隔夜空腹的血糖水平并不是最好的指标,因为每天的最低血糖水平在正常范围并不能保证每天的平均血糖水平也是在正常范围的。也就是说,隔夜空腹血糖高的话,那你的平均血糖水平一定是高的,但反之不然。餐后两小时的血糖水平(接近于每天的最高血糖水平)才是比较好的监测指标。而且,餐后两小时的血糖一定有所吃食物的直接影响,可以对控制食物有直接的指导作用。
你不能改变自己的基因,但能改变自己的生活习惯。只要能把血糖水平够控制到正常范围,就能减低自己患上II-型糖尿病的风险。只要血糖水平在没有药物作用下是可控的(利用食物控制和增加运动),那就说明体内的胰岛素功能没有被完全破坏,那就不是正真意义上的II-型糖尿病。
在目前的市面上和网络上,论述和指导对血糖控制的专家论文比比皆是,但是全都是泛泛而谈,没有一条是针对个人的。事实上,每一个人的生理条件是不一样的,肠胃里面的各种酶的质量的数量以及成分组合都是不一样的,所以,对于糖尿病高危人群和已处在糖尿病前期的人群来说,不可能有一条“放四海而皆准”的生活习惯(饮食和运动)方面的指导。比如说,有些人喝粥会引起血糖快速飙升,但有些人却是可以喝粥的(本猫喝粥和吃米饭的情况类似)。重要的是要每个人要找打符合自己的生活习惯。
作为一个生物统计师,本猫想回答这样的问题,能不能用数据建模来找到自己优化的食物种类和运动方式。于是开始了一个人的临床试验。从2016年开始,本猫于是开始用血糖仪每天观测自己餐后两小时的血糖水平。并且记录所吃的食物和运动的方式。

虽然一个人的临床试验很难做到随机化,而且连续的日子的食物和血糖水平会有很高的相关性。还要注意到每周7天的周期性因素(通常周末的食物会和平常不一样),所以在数据的观察中,要注意各种食物的随机搭配,也要有重复样本,在数据建模过程中,每5天取一个数据。看成是近似独立随机样本吧。这是本猫能想到的比较好的办法了。在这个(还在继续的)过程中,家里负责伙食的猫嫂,表现出非常的配合,在此表示衷心的感谢。在家里制作的食物菜点,都是不含糖的,而外出吃餐馆点菜的话,那菜点里面一定是重糖农油的,但是出去吃自助餐的话,那食物的选择又是可以自己有控制的。这对餐后血糖的控制,是有很大差别的。

可以看到,在开始做记录的时候,血糖值上下跳动很大,因为不清楚如何控制血糖,有点手足无措的感觉,还在摸索的过程中。红线是糖尿病的分界线,黄线是血糖正常值,在红黄线之间的,可以认为是糖尿病前期。本猫观察到,2018年以来,自己血糖值基本稳定在红线和黄线之间。只要血糖值不借助药物就可以控制,那就是个好的结果。和慢性病共存,这是现代人类对生命过程新的认识。对于那些无法治愈的病,就应该学会和病共存。
在建模过程中,血糖水平是因变量,食物类型和运动方式作为自变量。其中食物类型分成米面食物,素菜,肉类,水果,运动方式分为低强度(散步),中强度(伸展操),高强度(打球)。在每个食物大类里,还有很多子类。每隔5天取一个值,这样就有五组样本。每一组样本,可以认为是来自同一母体的重复样本。于是,可以用随机因子和固定因子的混合模型(Mixed Model)来做数据分析。而其中的随机参数可以用贝叶斯(Bayesian)方法来估计,而且随着新的数据的不断更新,模型也可以不断的更新。
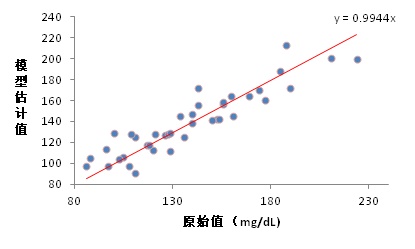
对于本猫的个体情况,数值统计模型的结果显示,模型的估计值和原始值有一个非常好的拟合度,线性系数为0.994。模型拟合度的Q-Q图显示,模型误差的分布很好的服从理论上的正态分布。

注意到这个模型不是群体模型(population model),而是一个个体模型(individual model),也就是说模型结果不具备群体普遍性,而是对本猫这个具体的个体有很好的针对性。这个模型最特殊的结果的就是把自变量的类型变量,针对本猫的个体情况精确的数值化了。
比如说,饭后两小时之内的低强度运动可以期望降低餐后2小时的血糖值14mg/dL,而中强度的运动可以期望降低餐后2小时的血糖值38mg/dL。少量鲜水果(半份)和水果干(葡萄干)不会增加血糖值,大部分的肉类都会增加血糖值(30 – 50mg/dL),本猫常吃的所有蔬菜都会降低血糖值,其中叶菜可以期望降低血糖值65mg/dL,而豆类菜可以期望降低血糖值30mg/dL,等等。这个结果对于本猫控制血糖值有着很好的指导意义。
因为糖化血红蛋白(A1c)可以反映过去三个月血糖控制的平均值,A1c被认为是一个长期的血糖指标。A1c不能显示血糖规律,它只是表示血糖控制好坏的一个指标。美国糖尿病学会的目标是A1c应控制在7%(154mg/dL)以下。研究表明,A1c在7%以下能减少糖尿病并发症的发生。美国内分泌学会的标准是 A1c应低于6.5%(140mg/dL)。接下来,本猫将试着建立个体统计模型,希望可以用每日自测血糖值来较好的预测A1c。
如果有读者属于糖尿病高危人群,一定要尽早检查你的血糖水平。并且可以利用本文的方法建立属于你自己的血糖值估计模型。不要过分迷信媒体上专家的建议,因为那些建议都是来自泛泛的群体统计模型,并不对你的个体情况会有很大的针对性。人们常常吐槽专家们的建议,但是并不知道专家们的建议都是基于不同的群体统计模型,而群体统计模型是排除个体差异性的,这也就是为什么常常会有吐槽专家的个体例子。
本猫认为,在大数据时代,群体医学统计模型的作用将会越来越小,而建立真正的个体化医学(personalized medicine)模型才是正确的方向,及所谓的精准医学(precision medicine)。有一个很直接的例子就是,大家都知道抽烟喝酒吃肥肉对身体健康不利,但是,在人群中放眼望去,抽烟喝酒吃肥肉的长寿者尽然比比皆是。这就是个体之间的差异,有遗传基因的原因,有个人体质的原因,有生活习惯的原因,等等。如果可以建立起个人的生物数据档案,根据个人的数据模型,那么,对于保持个人的身体健康会有很大的帮助。
更多我的博客文章>>>